Adding Interpretability to the Black-Box Inference Process of AI NTT
NTT has established “Evidence-Enhanced Decoding” technology as a new inference mechanism to enhance the reliability of output from its multimodal AI platform model that handles images and language.
Currently, development is progressing on a large-scale visual language model (LVLM) that integrates LLM and a pre-trained image encoder, enabling advanced multimodal inference. LVLM can directly input not only text but also images. Similar to LLM, which only accepts text, LVLM also generates “evidence for inference” intermediately from visual information and text input, and derives the final answer output by adding this evidence to the input sequence. Chain-of-Thought (CoT) is considered effective for improving inference capabilities and as an explainable inference method.
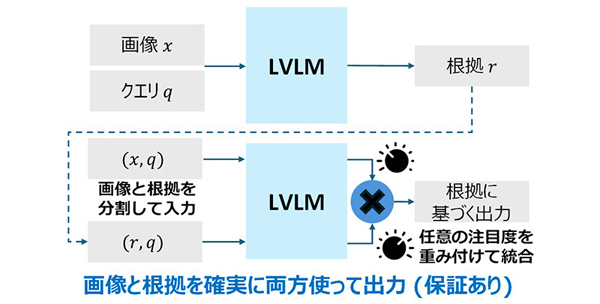
On the other hand, existing CoT mechanisms input images and evidence as a single sequence to generate the final output. Therefore, they lack a causal structure that necessarily uses the information contained in the evidence for inference, leaving the use of the evidence to the model. In other words, the final output from CoT is not guaranteed to be based on the content of the reasoning.
“Evidence-enhanced decoding” technology addresses the challenge that LVLMs tend to ignore their own generated reasoning when performing CoT. Unlike normal inference, it separates image-based inference from reasoning based on evidence, and combines them with weights. This allows the system to faithfully utilize information from both images and evidence to output an answer.
Evidence-enhanced decoding separates the probability that the LVLM predicts the next token into an image-conditioned distribution and an evidence-conditioned distribution. By multiplying these, it harmonizes the information obtained from the image and the information obtained from the evidence to output an answer. In this method, since the image and evidence are input to the LVLM separately, the use of evidence can be guaranteed.
“Evidence-enhanced decoding” technology suggests the possibility of giving interpretability to the LVLM inference process, which has previously been a black box. This makes it easier to apply LVLMs to fields that require more reliable and dependable inference systems, such as medical image diagnosis and conversational agents that handle critical cases involving human decision-making.
※Translating Japanese articles into English with AI