Establishing visual reading technology through LLM NTT
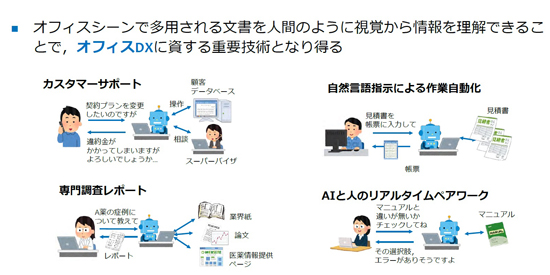
NTT has realized visual reading technology that uses large-scale language models (LLM) to understand documents, including visual information. In experiments, results have been obtained that suggest the possibility of realizing AI that can answer all kinds of questions while presenting document images, and is expected to become a core technology in DX.
This result has been adopted and introduced as tsuzumi’s adapter technology.
NTT is the first in the world to develop a new visual reading technology that uses LLM’s reasoning ability to visually understand documents. To achieve this, this research has developed a new adapter technology that can convert document images into LLM representations. Adapter technology becomes a module that bridges the image encoder and LLM. NTT also constructed an instruction performance dataset for various visual reading tasks.
This makes it possible for LLM to understand the content of a document by combining visual and linguistic aspects, and to perform any task without additional learning.
NTT has proposed ” visual reading technology” as a technology for understanding documents from visual information, similar to how humans understand information, and is conducting research and development with the aim of realizing this technology.